
Hummingbird Update
Mit dem Hummingbird Update führte Google 2013 eine umfassende Erneuerung seines Kernalgorithmus durch, die insbesondere die Bedürfnisse der Mobilgerätenutzer und der konv...
- 09 Okt., 2024
- 0 Kommentare
Ein Webcrawler ist ein Software-Programm, das automatisiert das Internet durchsucht und "scannt".
Suchmaschinen wie Google nutzen Webcrawler, um auf Webseiten neue Inhalte zu finden und listet diese in der Google Suchmaschine. Vorher fließen die gesammelten Informationen in einen Algorithmus ein, der diese Informationen bewerten und anschließend in den Google Index aufnimmt (oder auch nicht). Auf Basis der Bewertungen entstehen anschließend die Suchergebnisse, die wir von den Google Suchergebnissen (SERPs) kennen.
Hierbei geht's also um eine Software, die das Internet ständig nach neuen Webseiten und Inhalten (Texte, Bilder, Videos etc.) durchsucht. Jede Suchmaschine im Internet arbeitet auf Grundlage eines Webcrawlers, um ihre Datenbank zu füllen und zu aktualisieren. Um diese unendliche Anzahl von Seiten im Internet indexieren zu können, arbeiten diese Programme automatisiert. Dabei sind verschiedene Searchbots für verschiedene Funktionen zuständig. Ein Crawler kann die Texte analysieren, während ein anderer die Bilder ausliest.
Vielleicht kennst du den Begriff auch unter dem Namen Webcrawler, (Suchmaschinen-)Spider oder (Search-)bot.
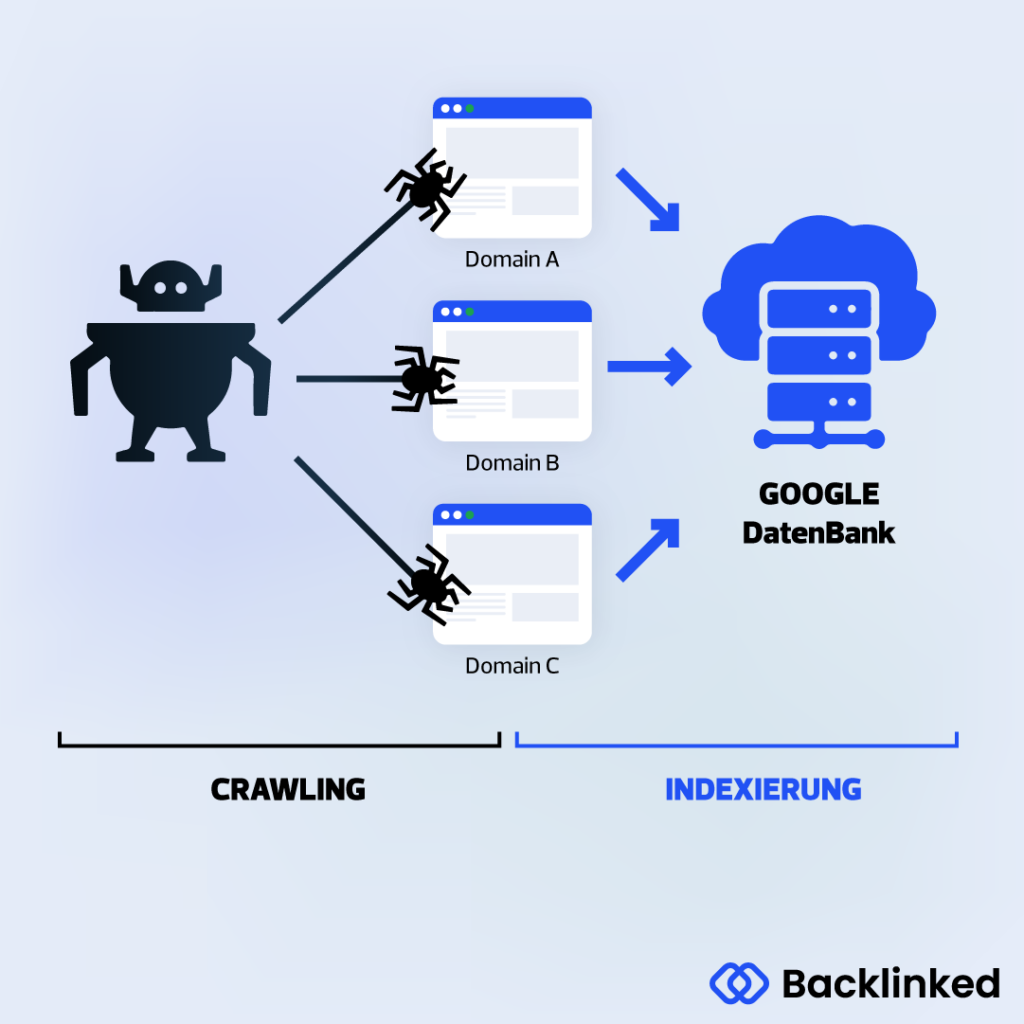
Nicht zuletzt, weil Google in Deutschland und den meisten anderen Länder die marktführende Suchmaschine anbietet, ist der Googlebot - der Google Crawler - am bekanntesten.
Ein Searchbot folgt prinzipiell jeder Seite im Internet, sofern diese auffindbar ist. Das ist allerdings sehr allgemein beschrieben - in der Praxis ist es wesentlich komplexer.
Die schiere Menge an Informationen im Internet macht es nahezu unmöglich, sicherzustellen, dass alle relevanten Daten erfasst wurden und keine wichtigen Inhalte übersehen werden. Webcrawler starten ihre Reise durch das World Wide Web mit einer vordefinierten Liste von Webseiten. Von diesen Ausgangspunkten aus verfolgen sie die auf den Seiten enthaltenen Hyperlinks, um zu weiteren Webseiten zu gelangen. Dieser Prozess wiederholt sich fortlaufend, wobei die Crawler von einer Seite zur nächsten springen und so ein immer größeres Netzwerk an verbundenen Webinhalten aufbauen. Durch dieses schrittweise Vorgehen versuchen Suchmaschinen, möglichst viele Informationen im Internet zu entdecken und zu indexieren. Dennoch sind die Vollständigkeit und Relevanz der gesammelten Daten nicht garantiert.
Google muss daher stark priorisieren und hat dafür das sogenannte Crawl Budget zur Verfügung. Jede Seite bekommt also vom Google Bot ein Budget, wie weit der Webcrawler sich durch die Seite sucht. Ist das Crawl Budget aufgebraucht, durchsucht der Crawler auch die Webseite nicht weiter.
Alle gefundenen Seiten (URLs) werden dann durch verschiedene Algorithmen nach bestimmten Kriterien sortiert und bewertet. Um welche Kriterien es sich handelt und wie diese bewertet werden, veröffentlichen die Betreiber von Suchmaschinen nicht, da es sich um ihre Geschäftsgeheimnisse handelt. Trotzdem gibt es bestimmte Rankingfaktoren, die laut Google & Co. wichtig sind, um von den Algorithmen positiv bewertet zu werden.
Es ist daher unter anderen die Aufgabe von SEO Agenturen, herauszufinden, wie die Algorithmen denken und arbeiten. Oft gibt es bewährte Taktiken, die sich mit den Jahren etabliert haben. Oft gibt es Maßnahmen, die nicht im Sinne von Google sind, die aber die Rankings positiv beeinflussen. Diese Taktiken nennt man "Black Hat SEO". Der Name soll aussagen, dass diese Taktiken nicht im Sinne von Google sind - das Gegenstück hierzu wäre White Hat SEO.
Falls du noch nicht ganz verstanden hast, welche Rolle ein Searchbot spielt...
Das folgende Video gibt unter anderem Aufschluss darüber, wie Crawling funktioniert und wie die Webseiten gerankt werden.
Durch sogenannte Logfiles des Webcrawlers kann ein Webmaster Informationen darüber bekommen, wer genau den Server ausforscht und die Seite "durchsucht". Er hat auch bestimmte Möglichkeiten, dem Searchbot den Zugang zu verwehren. Wenn du z.B. nicht möchtest, dass bestimmte Informationen über den Crawler abgerufen werden, kannst du sogenannte Meta Tags im HTML-Dokument hinzufügen. Das kannst du ebenfalls über die Robots.txt Datei mit der Kennzeichnung: „Disallow:/“ erreichen. Damit sagst du dem Webcrawler: "Diese URL bitte nicht crawlen, geschweige denn indexieren." Google checkt immer, ob es eine Regel in der Robots.txt gibt, bevor die Prüfung beginnt. Diese Textdatei legt die Regeln für die Bots fest, die auf die Seite zugreifen.
Du kannst auch festhalten, mit welcher Frequenz (via Google Search Console) oder wie viele Seiten der Googlebot durchsucht, damit bspw. nicht die Serverleistung beeinträchtigt wird.
Die interne Verlinkung von Webseiten spielt beim Crawlen von Webseiten eine große Rolle. Durch interne Verlinkungen versteht der Crawler deine Webseite und die verlinkten Informationen. So kommt der Webcrawler "von Stöckchen auf Steinchen". Bekommt er zum Beispiel bei jedem zweiten internen Link einen 404 Fehler (Seite nicht gefunden), könnte sich das negativ auf dein Crawl Budget auswirken.
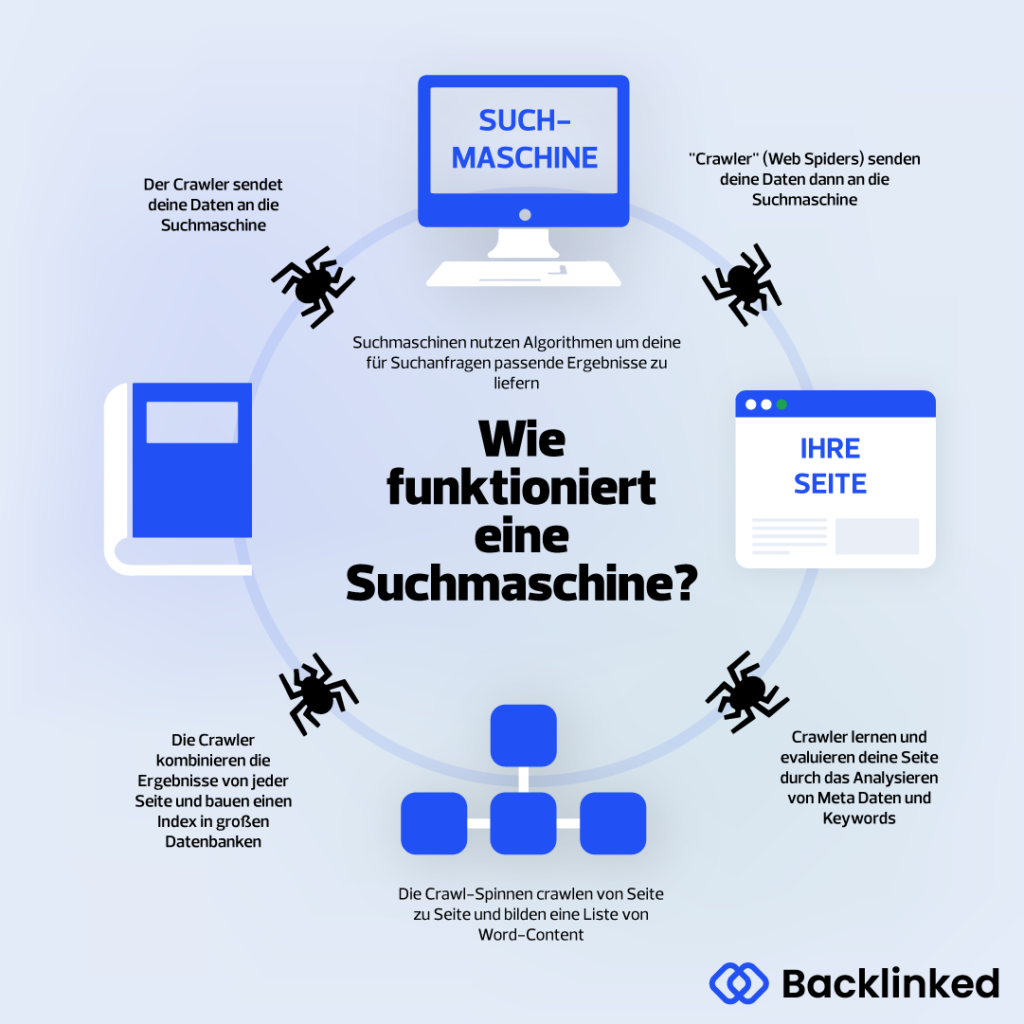
Ein Webcrawler kann auch dazu dienen, bestimmte Informationen aus Webseiten herauszufiltern. Preisvergleichseiten nutzen Crawler hauptsächlich, um aktuelle Preisinformationen zu erhalten. Auch Data-Mining ist ein typisches Anwendungsgebiet für die Searchbots.
SEO Tools wie ahrefs, Sistrix & Co. nutzen auch Webcrawler, um Daten für eine Webanalyse von Webseiten bereitzustellen. Das ist die Grundlage für die Arbeit von SEO-Analysten. Diese Daten, die der Crawler analysiert, werden entsprechend aufbereitet und zeigen dann bspw. Werte wie den organischen Traffic, der über bestimmte URLs auf deine Seite kommt. Eigene Tools von Google dazu nennen sich Google Search Console und Google Analytics. Diese hauseigenen Tools von Google sind dafür da, den Datenfluss zu analysieren und Probleme zu ermitteln. Diese Tools sind die Grundbausteine eines jeden SEO's.
Leider wird ein Webcrawler nicht nur für den Index der Suchmaschinen verwendet, sondern auch bspw. für das Sammeln von E-Mail-Adressen. Ein Scraper z.B. handelt inhaltsbasiert und nicht auf Grundlage der Meta-Informationen. Dieser dient dem Zweck Content abzugreifen und diesen zu kopieren bzw. wiederzuverwenden.
Bösartige Bots können erhebliche Probleme verursachen, von negativen Nutzerbewertungen über Serverüberlastungen bis hin zu Datensicherheitsverletzungen.
Für ein effektives Bot-Management solltest du daher differenziert vorgehen. Es ist entscheidend, dass legitime und hilfreiche Bots, wie beispielsweise die Crawler von Suchmaschinen, weiterhin ungehindert arbeiten können. Gleichzeitig müssen schädliche Bots zuverlässig erkannt und blockiert werden. Dienstleister wie Cloudflare bieten dafür spezialisierte Lösungen an. Auch kleinere Unternehmen mit begrenzten Ressourcen haben so die Möglichkeit, ein effektives Bot-Management zu implementieren.
Diese Ansätze zielen darauf ab, ein Gleichgewicht zwischen Sicherheit und Funktionalität zu schaffen, indem sie schädliche Bots abwehren und gleichzeitig den Betrieb nützlicher automatisierter Prozesse gewährleisten.
Ein Webcrawler kann eine Vielzahl von Aufgaben erledigen, die über das einfache Durchsuchen von Websites hinausgehen. Hier sind einige weitere Funktionen, die ein Searchbot ausführen kann:
Webcrawler haben in der Regel eindeutige Identifikatoren, sogenannte User Agents. Diese Kennungen ermöglichen es Webservern, die Herkunft der Anfragen zu erkennen.
Große Suchmaschinen wie Google verwenden verschiedene Webcrawler für unterschiedliche Zwecke. So gibt es bei Google separate Bots für die allgemeine Websuche, die Bildersuche, für Werbedienste wie AdSense und Google Ads, sowie für die Indexierung mobiler Websites. Diese tragen Namen wie "googlebot" oder "googlebot-mobile".
Andere bekannte Suchmaschinen haben ebenfalls ihre eigenen Webcrawler. Yahoo nutzt beispielsweise den "Yahoo!Slurp", während Bing den "bingbot" einsetzt. Auch der Webdienst Alexa verwendet einen eigenen Crawler namens "ia_archiver", um Daten zu sammeln.
Diese Identifikatoren ermöglichen es Website-Betreibern, den Zugriff bestimmter Crawler auf ihre Websites zu kontrollieren. Diese Kontrolle ist wichtig für das Management der Serverressourcen und den Schutz sensibler Inhalte.
Web Scraping und Webcrawling sind zwei unterschiedliche Methoden der automatisierten Datengewinnung aus dem Internet, die sich in ihren Zielen und Vorgehensweisen unterscheiden.
Während Web Scraper oft auf spezifische Daten oder Websites ausgerichtet sind, erkunden Webcrawler das Internet breiter und folgen Links von einer Seite zur nächsten. Web Scraping kann aggressiver vorgehen und die Leistungsfähigkeit von Webservern stärker belasten, wohingegen Webcrawling typischerweise rücksichtsvoller und regelkonformer erfolgt.
Eins steht fest: Ohne Webcrawler gäbe es auch keine Suchmaschinen. Sie bieten die Grundlage und sind quasi der Manager, der die Informationen der Webseiten sammelt. Wie bereits oben erwähnt ist die Google Search Console ein wichtiges Instrument, um Webcrawler zu beeinflussen und auch festzustellen, ob bestimmte Seiten gar nicht berücksichtigt werden. Somit ist es essenziell zu wissen, wie sie arbeiten und welchem Zweck sie dienen.
Um von den Suchmaschinen indexiert zu werden, sollte deine Website ideal vom Webcrawler durchsucht werden können. Dafür solltest du eine robots.txt-Datei anlegen und sensible Bereiche vor der Indizierung ausschließen. Ein weiteres essenzielles Instrument ist, die in der Google Search Console hinterlegte XML-Sitemap. In der Google Search Console kannst du außerdem überprüfen, ob der Googlebot alle wichtigen Bereiche einer Webseite erreichen und indexieren kann.
Du benötigst Hilfe dabei? Jetzt bei kreuzweise SEO Agentur unverbindlich anfragen!
Als Basis dient eine nach Möglichkeit flache sowie logische URL-Struktur, um es dem Crawler so einfach wie möglich zu gestalten. Zudem sorgt eine ordentliche Verlinkung (Trustlinks, sowie Backlinks) dafür, dass Webspider deine Seite auch besuchen. Wie du Backlinks aufbauen kannst, erfährst du im entsprechenden Beitrag. Um starke und nachhaltige Backlinks in kürzester Zeit aufzubauen, kannst du Kontakt mit uns aufnehmen oder deinen Linkaufbau selbst auf unserem Marktplatz planen.
Pro Seite hat jeder Searchbot nur einen limitierten Zeitraum zur Verfügung - auch Crawl Budget genannt. Mit SEO sowie einer verbesserten Navigation und dem Dateiumfang kannst du als Webseitenbetreiber das Crawl Budget des Googlebots beispielsweise besser ausnutzen. Gleichzeitig steigt das Budget durch zahlreiche eingehende Links und eine stark frequentierte Seite.
Mit dem Hummingbird Update führte Google 2013 eine umfassende Erneuerung seines Kernalgorithmus durch, die insbesondere die Bedürfnisse der Mobilgerätenutzer und der konv...
Beim Fred Update handelt es sich um eine Reihe von Anpassungen am Google Algorithmus, die auf die Qualität von Inhalten abzielen. Definition Mit dem Fred Update hat...

Das Google Panda Update hat seit seiner Einführung die Welt der Suchmaschinenoptimierung nachhaltig verändert. Mit diesem Update hat Google im Jahr 2011 seinen Ranking-Al...